
Attitudes towards L2-Varieties in a Foreign Language
1 TU Dortmund
1 Introduction and Background
This essay serves the purpose of going back to one of Ludger Hoffmann’s first works, namely his doctoral thesis (Zur Sprache von Kindern im Vorschulalter, 1978) and his remarks on regional dialects and attitudes towards them. This exploratory study looks into the role of intonation in the perception of non-native accents as well as into attitudinal reactions of native speakers of German towards foreign-accented speakers of Korean, a language that is neither the speakers’ nor the listeners’ L1 but where knowledge about the L2 is available. Korean speech samples of four female speakers with three different L1s (French, Italian and German) in three different versions (unaltered, no intonation, intonation only) were each presented to a group of German L1-speakers. They also had to fill out a questionnaire covering social aspects of language perception to find out whether the speakers and their output were judged differently regarding their L1 and the version of the sound sample. The findings of this study show a tendency to rate those samples more favourably in which speaker and listener share an L1 (German).
Studies on foreign accent and dialect perception [1]; [2]; [3] show that deviations from the standard variety evoke attitudinal responses – sometimes positive, sometimes negative ones. Dialect speakers of German for example were long seen as being less competent linguistically because their use of dialect was linked to their assumed social status – an attitudinal attribution that was rejected by Hoffmann [3] in his doctoral thesis. Attitudinal attributions are not limited to certain dialects within a language; they can be observed with all kinds of linguistic output, including L2 varieties, which will be the focus of this paper. Spoken language, as Lambert/Dil [4] put it, is always tied to social group membership and serves as an identifying feature which inevitably evokes attitudes. These listener attitudes may depend on a number of variables, e.g. individual or societal experience with speakers of certain linguistic varieties or languages; they are also tied to linguistic properties (e.g. [2]). It has also been established that the strength of an accent can influence social judgments which are attributed to a speaker ([2]). Listeners have to be reasonably familiar with a variety to link it to a certain group and to draw on their knowledge of properties associated with that group. Hence, a strong accent is more likely to evoke a strong affective reaction than a light accent, because the strong accent is more prototypical. In this study [2], speakers with a light accent were rated more favourably than those with a strong accent in terms of status, but at the same time speakers with a strong accent were attributed more solidarity.
The speech samples used in the exploratory study discussed in this paper were taken from the Korean talk show minyodeulri ssuda: In this show expat women from all over the world discuss different topics in Korean which is the L2 they acquired as adults.
To somebody who is familiar with Korean, these women’s pronunciations are different compared to a native speaker, e.g. the host of the show, but they also sound quite different compared to each other in terms of their accents in Korean. Further, I noted it to be fairly easy to identify some of the women’s L1 without even looking at the screen, albeit restricted to L1s I am familiar with e.g. German, French, Italian.
Attitudes, as mentioned above, draw on some kind of knowledge (often stereotypic) a listener has about a certain group of speakers that is tied to linguistic properties/phenomena. For example, Germans tend to romanticise a French accent, and usually the attitude towards a French accent is profoundly positive (e.g. [5]). L1 German speakers know these accents connected to their own language, and in most cases confined to their own language only (a French accent in German as opposed to a French accent in any other language). Do a French or an Italian accent in Korean evoke similar attitudinal reactions from L1 German speakers? If this is the case, the French accented speech sample is expected to be rated more favourably than the Italian accented one. The features that people draw on when identifying the first language of a speaker are the same that evoke attitudes. Did they express a stronger attitude towards accents they identified or did it not make any difference at all? If intonation were at the core of perceiving language and linguistic cues in a way that allows L1 or L2 identification, the listeners’ responses to the various conditions should show that they reacted more strongly when only given intonational cues as opposed to segmental ones. Two of the speech samples feature German accents, one more prototypical than the other. Since humans are known to react more favourably to what is familiar to them, the German accented samples are expected to evoke more positive reactions compared to the samples featuring a different L1. The more prototypically sounding L1 German sample would then be expected to be rated best out of all samples by an L1 German audience. One way to test this is to let a group of listeners react to only the intonation of the examples versus the examples stripped of all intonational information and compare the results with the reactions to the unaltered speech samples.
2 Study Design
In the exploratory study, 45 L1 German university students were presented with four unaltered sound samples (original version – og) taken from the tv show minyodeulri ssuda and a questionnaire covering social aspects of language perception such as sympathy and competence. Each sound sample contained an utterance by one speaker (L1 French, L1 Italian and 2 L1 German speakers) that was approximately of the same length, namely between 11 and 16 seconds. They did not have the exact same length because they are naturally occurring utterances and to cut them off after a certain number of seconds would have made them sound unnatural. The speakers were chosen based on a small pre-test: First, I picked out three speakers whose accents were most accessible, i.e. very easy to identify. Another L1 German speaker was chosen because I found her accent less easy to pinpoint compared to the other L1 German speaker. To verify my (mostly) intuitional choices regarding the accents’ prototypicality, I also asked L1 Korean speakers for their opinion. They identified all accents correctly and also agreed with me that one of the L1 German samples showed an accent which was a lot easier to identify than the other, hence the labels ‘strong’ and ‘light’ are used later on. The speakers will be referred to as s1 (L1 French), s2 (L1 Italian), s3 (L1 German, strong accent), s4 (L1 German, light accent) in the following.
The questionnaire comprised attitude-related questions as well as questions regarding information on the linguistic background of the subjects. The participants were asked to rate the speakers as sounding either sympathetic or unsympathetic. They also were requested to rate what the samples sounded like to them in a binary opposition scale as being either pleasant or unpleasant, melodic or unmelodic, and soft or hard. By doing so, the questionnaire covered different dimensions of attitudes and judgments. The participants listened to the four speech samples two times in a row before filling out the questionnaire (condition og).
The experiment was repeated twice with comparable listener groups and the same sound samples, but manipulated to have no intonation (condition nint) and to have intonation only (condition int) by removing pitch in Praat and by low pass filtering up to 500 Hz, respectively.
The participants were 135 native speakers of German with no prior knowledge of Korean, divided evenly between condition og (N=45), condition nint (N=43), and condition int (N=47).
3 Results
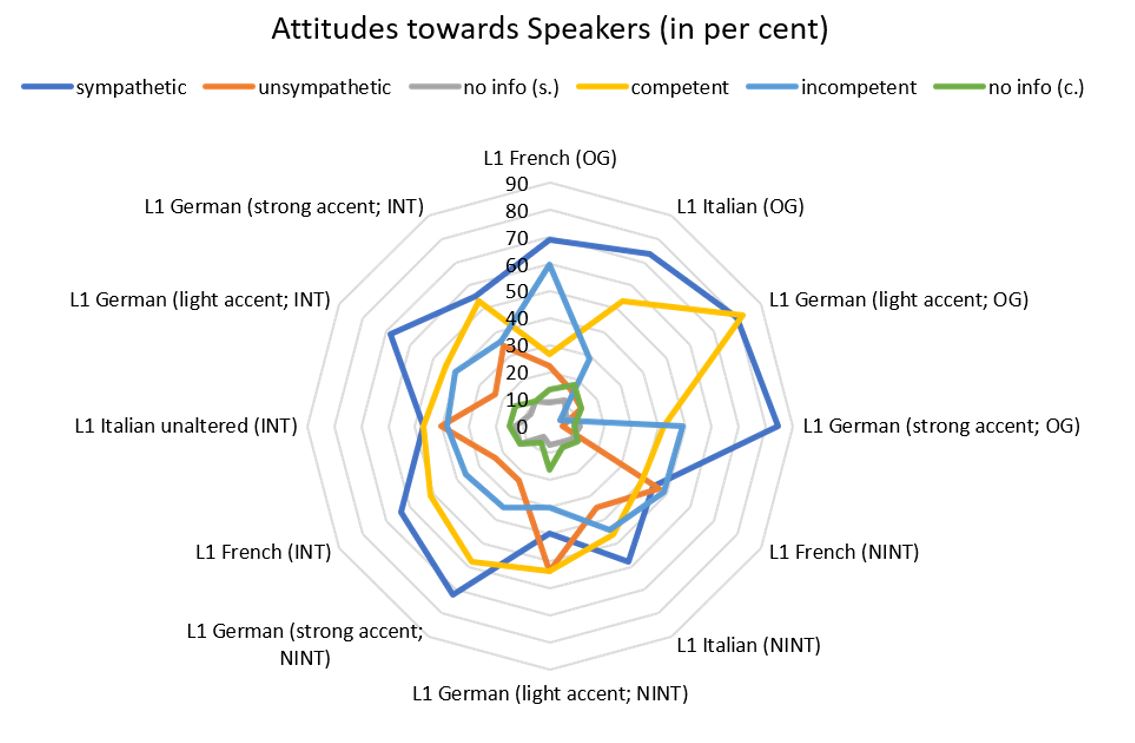
Figure 1 Attitudes towards speakers (in per cent)

Figure 2 Perception of Speech Samples in per cent
A comparison of the collected data concerning attitudes (see Figure 1) shows that there is a tendency to rate those samples more favourably in which speakers and listeners share an L1, i.e. German. Both German speakers were judged as being more sympathetic compared to the speakers with other L1s.
The two L1 German examples were assessed very differently, with the one featuring a stronger accent sounding the most pleasant, melodic, and soft out of all examples while the one featuring a lighter accent was rated least favourably out of all the speech samples.
Similar observations can be made for the assessment of the listeners’ attitudes towards the speakers. S4 sounded the most sympathetic (and competent) whilst s3, with a less prominent accent, was rated as being the most unsympathetic one out of all four speakers, albeit only slightly less competent than s4. The link between linguistic proficiency and competence that was presented and observable under condition og is lost completely when the sound of the examples is monotonised.
Overall, the speech samples, (see Figure 2) with the exception of s3 – L1-German with a light accent – were perceived as sounding more unpleasant than pleasant. A larger portion of participants rated s3 and the L1-French example (s1) as sounding melodic rather than unmelodic. The former was also categorised as sounding much softer than all the other examples. Compared to the other two conditions, a rather large number of participants abstaining from choosing a category is notable. To test whether the difference between the three conditions is statistically significant, the data was coded as follows: It was coded for each response whether the response given by the participant was positive regarding sympathy or not. A logistic mixed effect model, in which the positivity of the response was predicted by the condition, was computed using the lme 4 package in R. The model included “condition” as a predictor, and “sympathy” as the dependent variable, as well as random intercept for “participant” to make up for inter-participant variance. Condition og was defined as the baseline condition, to which the other two conditions were compared. The results revealed that the speakers were rated as sounding sympathetic significantly less for condition int compared to the baseline condition og (estimate = -1.07, SE = 0.29, z = -3.75, p < .001) as well as for condition nint, compared to the baseline condition og (estimate = -1.43, SE = 0.29, z = -5.02, p < .001).
In conclusion neither intonation, nor segmental information alone seem to lead to the same level of ratings for sympathy as the unaltered speech sample does.
4 Conclusion
The testing of the sociolinguistic category “sympathy” showed that the manipulation of the sound files had a statistically significant effect on listeners’ attitude towards the speakers but the tendencies remained the same under all conditions. The hypothesis that intonational properties of language have the biggest influence on language perception processes has to be rejected.
Under condition og the L1 German speakers were rated more favourably for sympathy compared to all the other speakers. S3, with a lighter accent, was attributed less sympathy compared to s4 while s3 was rated as being more competent – an observation that is similar to the findings of other studies (e.g. Dragojevic et al. 2017). Both s3 and s4 possibly sound more familiar to the L1-German audience than the other two examples. The fact that both L1-Germans (s3 and s4) and their way of speaking were perceived as sounding more pleasant and melodic than the other speakers and examples points to the factor of familiarity at work here. To verify this, one could repeat the study with native speakers of French and Italian and samples with a stronger and a lighter French /Italian accent in Korean in order to find out if the reaction patterns are comparable. Under conditions nint and int s4 was still perceived as being the most sympathetic one while this does not hold true for the lightly-accented one (s3). This, again, hints at the strongly accented example as being more prototypical and, thus, more familiar sounding which enables listeners to identify and judge it accordingly.
By listening to different learner varieties two times in a row the participants must have acquired and retrieved some kind of linguistic knowledge, maybe based on similarities and differences in pronunciation, that enabled them to categorise the examples. This as well as their feel for language is thought to have an impact on the perception process. A problem present in all studies relying on and involving implicit knowledge and attitudes is that the cues that lead to certain assumptions are not accessible, neither to the listeners nor to the researchers. It is common for participants to be unable to verbalise neither their attitudes and observations, nor the linguistic knowledge that is the basis of their sociolinguistic judgments [6]. It is, of course, possible to alter parameters and measure differences in reaction, but it is near impossible to alter one parameter whilst keeping all the others intact. If speech samples are altered to have no intonation or to have intonational properties only, the voice quality automatically changes as well. So, further testing would be needed to isolate crucial underlying factors in perceptual evaluation processing.
References
[1] Bröcher-Drabent, Kirsten (2018): Aussprache und Wahrnehmung. Eine empirische Studie zur Rezeption von L2-Varietäten des Deutschen. Tübingen: Stauffenburg.[2] Dragojevic, Marko; Giles, Howard; Beck, Anna-Carrie; Tatum, Nicholas T. (2017): The fluency principle. Why foreign accent strength negatively biases language attitudes. In: Communication monographs 84 (3), p. 385–405.
[3] Hoffmann, Ludger (1978): Zur Sprache von Kindern im Vorschulalter. Eine Untersuchung in zwei Kindergärten aus dem niederdeutschen Sprachraum. Köln [u.a.]: Böhlau.
[4] Lambert, Wallace E.; Dil, Anwar S. (1972): Language, psychology, and culture. Essays. Stanford (CA): Stanford University Press.
[5] Settinieri, Julia (2011). Soziale Akzeptanz verschiedener Normabweichungen in der L2-Aussprache Deutsch. In: Zeitschrift für Interkulturellen Fremdsprachenunterricht – Didaktik und Methodik im Bereich Deutsch als Fremdsprache 16 (2), p. 66–80.
[6] Labov, William (2006): A sociolinguistic perspective on sociophonetic research. In: Journal of Phonetics 34 (3), p. 500–515.